

Običajno najprej oblikujemo ničelno hipotezo (H0), ki pravi, da med vzorčno in populacijsko aritmetično sredino ni značilnih razlik. S Studentovo t-test metodo (ang. Student’s t-test) preverjamo hipoteze, kot so npr. ‘Zadovoljstvo ne vpliva na delovno uspešnost zaposlenih.’ ali ‘Oblika spletne strani vpliva na obiskovalca spletne strani.’.
V splošnem poznamo dva tipa t-test analize, in sicer:
- enostranski (ang. One-tailed test), kjer predpostavljamo, da je vzorčna aritmetična sredina večja ali manjša od populacijske, in
- dvostranski (ang. Two-tailed test), kjer predpostavljamo, da vzorčna in populacijska aritmetična sredina nista enaki oz. sta različni.
V praksi se najpogosteje uporablja dvostranska t-test analiza, s katero preverjamo hipoteze kot so npr. ‘Med moškimi in ženskami obstajajo razlike v nakupnih navadah.’ ali ‘Mlajše generacije pogosteje uporabljajo svoj mobilni telefon kot starejše generacije.’. V primeru tovrstnih hipotez z dvostransko analizo t-testa torej preverjamo ali se aritmetični sredini dveh skupin (npr. moški in ženske, starejši in mlajši) med seboj razlikujeta pri določeni lastnosti (npr. nakupne navade, uporaba mobilnega telefona).
Osnova za primerjavo dveh skupin pa je seveda izračun vrednosti t statistike in odločitev o stopnji značilnosti α.
- Stopnja značilnosti (α – alfa) (tudi Stopnja signifikantnosti) (ang. Significance level) je verjetnost za napako 1. vrste, ki jo je uvedel R. A. Fisher. Napaka 1. vrste (ang. Error of first kind) je torej verjetnost, da zavrnemo pravilno domnevo oz. da v populaciji ne obstaja nobena resnična povezanost in je torej ničelna hipoteza pravilna. Najpogosteje uporabljamo stopnjo značilnosti v višini 0,05, v uporabi pa sta tudi stopnji 0,01 in 0,001.
Ko izračunamo vrednost t statistike preverimo ali se le-ta nahaja v kritičnem območju t porazdelitve ali izven njega.
Kritično območje (ang. Critical region) imenujemo območje t porazdelitve, kjer vrednosti t statistike odstopajo od populacijske aritmetične sredine v tolikšni meri, da ne moremo govoriti o enakosti vzorčne in populacijske aritmetične sredine, torej ne moremo sprejeti ničelne hipoteze (H0), ampak sprejmemo osnovno hipotezo (H1) ob stopnji značilnosti α. Kje se kritično območje nahaja, je odvisno od izbrane stopnje značilnosti, saj le-ta določa faktor oz. vrednost začetka kritičnega območja na krivulji x.
V primeru dvostranskega testa se kritično območje nahaja na obeh straneh t porazdelitve.
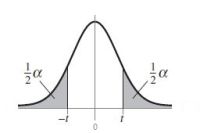
V primeru enostranskega testa se kritično območje nahaja na eni, pozitivni ali negativni, strani t porazdelitve.
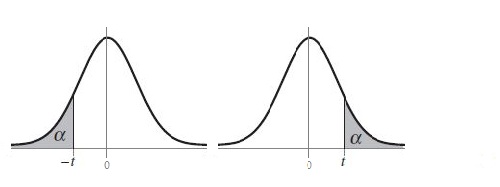
Torej, v kolikor se vrednost t statistike npr. pri primerjavi nakupnih navad moških in žensk nahaja v kritičnem območju, rečemo, da obstajajo statistično značilne razlike v nakupnih navadah med moškimi in ženskami, kar lahko trdimo s 5 % stopnjo značilnosti (v primeru, da je v naši analizi α=0,05).
Pri izvedbi analize ne smemo pozabiti na upoštevanje predpostavk metode. In sicer, Studentova t-test metoda predpostavlja, da so podatki obeh skupin normalno porazdeljeni in da sta varianci med skupinama (vsaj približno, torej pri določeni stopnji značilnosti) enaki.
- Normalno porazdelitev (ang. Normal distribution, Gaussian distribution) (tj. porazdelitev, kjer je M=0 in SD=1) lahko preverjamo s pomočjo različnih testov normalnosti (npr. Kolmogorov-Smirnov test ali Shapiro-Wilkov test) ali pa grafično s pomočjo histograma (ang. Bar chart) in uporabo krivulje normalnosti (ang. Normality curve), kjer se ne smemo srečati s spremenljivkami, asimetričnimi v desno ali v levo.
- Enakost varianc (ang. Equality of variances) preverjamo z različnimi parametričnimi testi enakosti varianc (npr. Levenov ali Bartlettov test) ali neparametričnimi testi (npr. Kruskall-Wallis test).
Zadnja predpostavka analize je, da so podatki obeh skupin oz. obeh vzorcev zbrani med seboj neodvisno (ang. Independent samples). Tega sicer ne moremo preveriti v samih podatkih, a kadar se pri analizi pojavijo nesmiselni rezultati je lahko večkrat napaka prav v neustrezno zbranem vzorcu. Zato je zelo pomembno, da že pri pripravi vprašalnika poskrbimo za kakovostno in pravilno zbran vzorec respondentov in se s tem problemom ne srečamo pri izvajanju statističnih analiz podatkov.
Se ukvarjate s statistično analizo podatkov in potrebujete pomoč? Potrebujete izračun t statistike? V podjetju BenSTAT vam bomo svetovali in poskrbeli za kakovostno analizo vaših podatkov. Oglasite se: info@benstat.si!




